Intro
이 포스트는 크롤링 시작하기 포스트에 의존합니다. 이전 포스트를 먼저 보시는걸 추천합니다.
웹 크롤링에 대해 알아보다가 뜬금없이 데이터 저장? 이라고 할 수도 있겠다. 지금까지 웹 크롤링 결과를 터미널에 출력하거나 txt파일로 만들었다. 하지만 데이터를 수집하는데만 관심이 있다면 모를까 수집한 데이터를 분석하려면 이런 방법으로는 유용하지않다.
이번에 데이터를 관리하는 방법에대해 알아보자. 굳이 웹 스크레이핑이 아니더라도 다른 애플리케이션을 만들 때 데이터베이스는 필수이기 때문에 익숙해 질 필요가 있다.
미디어파일
미디어 파일을 저장하는 방법은 크게 두 가지이다. 하나는 참조를 저장하는 것, 다른 하나는 파일 자체를 저장하는 것 이다.
파일 참조 저장은 간단하다. 파일이 위치한 URL을 저장하기만 하면 끝. 이 방법에는 여러 장점이 있다
- 스크레이퍼가 파일을 내려받을 필요가 없으므로 빠르고 가볍다.
- URL만 저장하므로 컴퓨터의 공간도 확보할 수 있다.
- 코드짜기가 쉽다.
- 호스트 서버의 부하도 적다
물론 단점도 있다.
- 외부에 있는 파일은 언제든 바뀔 수 있다.(웹 마스터에 의해)
- 파일을 사용하려는 시점에 파일이 사라져있을수도 있다.
- 파일을 내려받으면 실제 사람이 사이트를 보는 것처럼 보일 수 있다.(장점이다!)
대부분의 사람은 스크레이핑 한 데이터를 단순히 저장만 해 놓고 만족하지는 않는다. 분석을 위해서는 실제 파일저장이 필수다.
파이썬 3.X 에서는 url.request.urlretrieve을 사용하여 원격 URL의 파일을 내려받을 수 있다.
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("html://www.pythonscraping.com")
bsObj = BeautifulSoup(html, 'html.parser')
imageLocation = bsObj.find("a", {"id":"logo"}).find("img")["src"]
urlretrieve (imageLocation, "logo.jpg")
이 코드는 http://www.pythonscraping.com에서 로고를 내려받아 스크립트를 실행한 디렉터리에 logo.jpg라는 이름으로 저장한다.
MySQL
오픈소스 관계형 데이터베이스 관리 시스템.
기본 명령어
일단 처음 로그인하면 데이터를 추가할 데이터베이스가 없으니 만들어야 한다.
CREATE DATABASE scraping;
그리고 이 데이터베이스를 사용하겠다고 알려준다.
USE scraping;
오! 아주 쉽다. 이제 스크랩한 웹 페이지들을 저장할 테이블을 만들자.
CREATE TABLE pages (
id BIGINT(7) NOT NULL AUTO_INCREMENT,
title VARCHAR(200),
content VARCHAR(10000),
created TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
후! 테이블에 목록들까지 추가했다. 각열의 정의는 세 부분으로 나뉜다
- 이름(id, title, created 등)
- 변수 타입(BIGINT(7), VARCHAR, TIMESTAMP)
- 옵션으로 추가속성(NOT NULL, AUTO_INCREMENT 등)
열 목록 마지막에는 반드시 테이블의 키를 정의해야 한다. MySQL은 이 키를 사용해서 테이블 콘텐츠를 빨리 검색할 수 있도록 준비한다.
쿼리를 실행하고 나면 언제든 DESCRIBE 명령으로 테이블 구조를 확인할 수 있다.
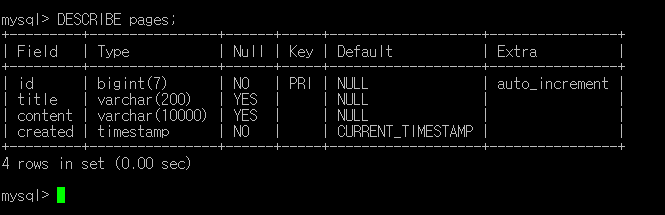
이제 데이터를 삽입해보자.
INSERT INTO pages VALUE(
1,
'Test Page Title',
'this is test page content',
'2017-10-26-16:00:00'
);
성공했다면 삽입한 데이터를 확인해 본다.
SELECT * FROM pages WHERE id = 1;
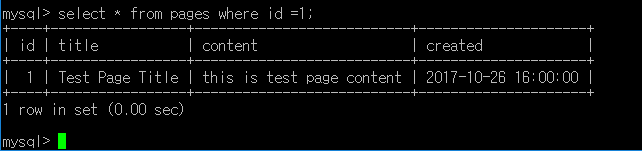
이 문법은 pages테이블에서 id가 1인 것을 모두 선택하라는 의미다.
이 외에도 DELETE나 UPDATE문도 사용법이 비슷하니 자세한 사용법은 여기를 참고하자.
파이썬과 연결
아쉽게도 파이썬에는 MySQL이 내장되어 있지 않다. 따로 설치해야하는데 pip install pymysql 한줄이면 끝난다.
다음 코드에서 비밀번호 부분은 각자 설정한 비밀번호로 바꾸자.
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='None', db='mysql')
cur = conn.cursor()
cur.execute("USE scraping")
cur.execute("SELECT * FROM pages WHERE id = 1")
print(cur.fetchone())
cur.close()
conn.close()
여기에는 새로운 객체타입이 있다. 하나는 연결 객체(conn)이고, 하나는 커서 객체 (cur)이다.
연결하나에 커서 여러 개가 있을 수 있다. 연결 객체는 데이터베이스 연결에 관여하지만, 그 외에도 데이터베이스에 정보를 보내고, 롤백을 처리하고 새 커서 객체를 만드는 역할도 한다.
커서는 어떤 데이터베이스를 사용 중인지 같은 상태 정보를 추적한다. 데이터베이스가 여러개 있고 이들 전체에 정보를 저장해야 한다면 커서도 여러 개 필요하다. 커서를 다 사용하면 반드시 닫아야한다. 그렇지않으면 연결누수현상이 발생하는데 이는 더는 사용하지않는 연결을 계속 유지하는 현상이 쌓여 결국 데이터베이스가 다운될 수도 있다.
자 이제 스크레이핑 결과를 데이터베이스에 저장하는 일을 해보자. 이전에 만들었던 위키백과 스크레이퍼를 재활용 하자.
웹 스크레이핑을 하면서 유니코드 텍스트를 다루는일이 좀 어려운데 MySQL은 기본적으로 유니코드를 처리하지않는다..ㅠ
검색을 하다보니 기능을 켤수 있단다.
이제 우리 데이터베이스에 유니코드를 알려주자.
ALTER DATABASE scraping CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE pages CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
위의 코드는 데이터베이스와 테이블 두 열의 기본 문자셋을 utf8mb3에서 utf8mb4_unicode_ci로 바꾼다.
이제 준비가 끝났으니 다음과 같은 코드를 짜서 실행해 보자.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='None', db='mysql', charset='utf8')
cur = conn.cursor()
cur.execute("USE scraping")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute(
"INSERT INTO pages (title, content) VALUES (\"%s\",\"%s\")",
(title, content)
)
cur.connection.commit()
def getLinks(articleUrl):
html = urlopen("https://en.wikipedia.org" + articleUrl)
bsObj = BeautifulSoup(html, "html.parser")
title = bsObj.find("h1").find("span").get_text()
content = bsObj.find("div", {"id":"mw-content-text"}).find("p").get_text()
store(title, content)
return bsObj.find("div", {"id":"bodyContent"}).findAll("a",
href=re.compile("^(/wiki/)((?!:).)*$"))
links = getLinks("/wiki/Kevin_Bacon")
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
finally:
cur.close()
conn.close()
마찬가지로 password부분은 각자 설정한 비밀번호를 입력해 둔다.
store함수가 추가됬는데 이 함수는 문자열 변수 title과 content를 받고, 이 변수를 INSERT문에 추가한다. 커서는 INSERT문을 실행하고, 자신의 연결을 통해 데이터베이스에 보낸다.
커서는 데이터베이스와 자신의 컨텍스트에 관한 정보를 갖고 있지만, 정보를 데이터베이스에 보내고 삽입하려면 연결을 통해야한다. 커서와 연결이 어떻게 구분되는지 잘 보여주는 함수다.
마지막으로, 코드 마지막 부분에서 finally문을 메인루프에 추가하여 어떤일이 일어나도 프로그램을 종료하기전에 반드시 커서와 연결을 닫는다. 웬만하면 try-finally문을 사용하자!
이 외에도 pymysql에는 유용한 함수가 아주아주아주 많다. 반복하지만 데이터베이스를 배워두면 대부분의 애플리케이션에서 활용할 수 있기때문에 배우는걸 추천한다!