Intro
이 포스트는 폼과 로그인 뚫기 포스트에 의존합니다. 이전 포스트를 먼저 보시는걸 추천합니다.
사작하기에 앞서 자바스크립트와 Ajax, 동적 페이지 등의 개념을 익히고 가자.
클라이언트쪽 스크립트 언어는 웹 서버가 아니라 브라우저 자체에서 동작하는 언어다. 그중에 자바스크립트는 현재 웹에서 가장 널리 쓰이고 잘 지원하는 스크립트 언어다.
자바스크립트는 웹 페이지 대부분에 들어있을정도로 단순하지만 강력하다. 페이지 소스 코드에서 <script>태그 부분에 들어있다.
연산자나 루프, 배열 같은 문법적 요소는 일부 비슷하지만, 약한 타입과 스크립트에서 시작된 성격 때문에 다른 프로그래밍 언어에 익숙하다면 이해하는데 약간 노력이 필요할 수 있다.
다음 코드는 재귀함수로 피보나치 수열을 계산한 뒤 브라우저의 개발자 콘솔에 출력하는 코드다.
<script>
function fibonacci(a,b){
var nextNum = a + b;
console.log(nextNum + " is in the Fibonacci sequence")
if(nextNum < 100){
fibonacci(b, nextNum);
}
}
fibonacci(1, 1);
</script>
모든 변수앞에 var가 있다. 자바스크립트에서는 함수도 변수처럼 선언하여 사용할 수 있다는 대단히 좋은 기능이 있다.
예를들어
<script>
var fibonacci = function(){
var a = 1;
var b = 1;
return function(){
var temp = b;
b = a + b;
a = temp;
return b;
}
}
var fibInstance = fibonacci();
console.log(fibInstance() + " is in the Fibonacci sequence");
console.log(fibInstance() + " is in the Fibonacci sequence");
console.log(fibInstance() + " is in the Fibonacci sequence");
</script>
변수 ‘fibonacci’ 는 함수로 정의됐다. 이 함수가 반환하는 값은 함수이며, 반환된 함수는 피보나치 수열에서 점점 커지는 값을 출력한다.
여태까지 우리가 웹 서버와 한 통신은 페이지를 가져올 때 일종의 HTTP 요청을 보낸 것뿐이다. 페이지를 새로고침하지 않고 폼을 전송하거나 서버에서 정보를 가져오는 경험이 있다면 Ajax를 통한 것 이다.
Ajax는 언어가 아니라 특정 작업을 하기 위해 사용하는 기술의 묶음? 정도이다.
Ajax는 비동기 자바 스크립트와 XML(Asynchronous Javascript and XML)의 약자이며, 서버에 별도의 페이지를 요청하지 않고 정보를 주고받기 위해 사용한다. 그러니까
이 서버는 ‘Ajax’로 만든 겁니다.
가 아니라
이 폼은 ‘Ajax’를 써서 웹 서버와 통신합니다.
라고 해야한다.
마찬가지로 DHTML(Dynamic HTML)도 같은 목적을 위해 사용하는 기술을 묶어 부르는 말이다.
DHTML은 클라이언트 측 스크립트가 페이지의 HTML 요소의 변화에 따라 바뀌는 HTML이나 CSS이다. 커서를 움직여야 버튼이 나타나거나, 클릭하면 배경색이 바뀌거나, Ajax 요청으로 새로운 컨텐츠가 나타날 수도 있다.
이런 페이지들을 스크립팅 할때 무작정 페이지소스를 긁어오기만 한다면 로딩페이지만 긁어오거나 아무 의미없는 데이터만 가져올 수 있다.
이제 Ajax나 JQuery 뒤에 숨어있는 데이터를 긁어오는 방법을 알아보자.
셀레니움
전 포스트에서 requests를 이용해 네이버에 로그인 하려했지만 실패했었다. 프런트 단에서 자바스크립트를 통해 로그인처리를 하기 때문인데, 셀레니움을 사용하면 쉽게 가능하다.
이젠 너무나도 익숙한 패키지 설치방법.
$ pip install selenium
셀레니움은 원래 웹사이트 테스트 목적으로 개발됐지만, 강력한 웹 스크레이핑 도구로 사용할 수 있다.
셀레니움에는 자체적인 웹 브라우저가 들어 있지 않으므로 다른 브라우저가 있어야 동작한다.
보통 사용하는 파이어폭스나 크롬 등을 이용할 수 있다.
스크립트가 요란하게 브라우저를 띄우고 화면을 보여주는게 싫다면 조용히 백그라운드에서 실행되는 브라우저인 팬텀JS라는 도구도 있다. 나는 크롬을 사용하겠다.
일단 네이버 로그인 폼에서 마우스 우클릭 후 검사.
개발자 콘솔에서 태그의 id나 name 속성을 찾아본다. 그게 제일 중요하니까.
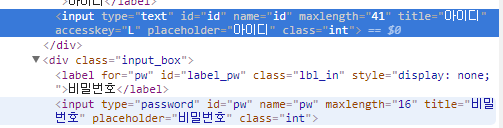
네이버는 아이디는 ‘id’ 비밀번호는 ‘pw’로 되어있는걸 볼 수 있다.
로그인 버튼을도 검사해 보자. 폼과 로그인 뚫기포스트 에서 설명했듯이 네이버 홈페이지가 아닌 폼 데이터를 처리하는 페이지에 요청을 보내야한다.
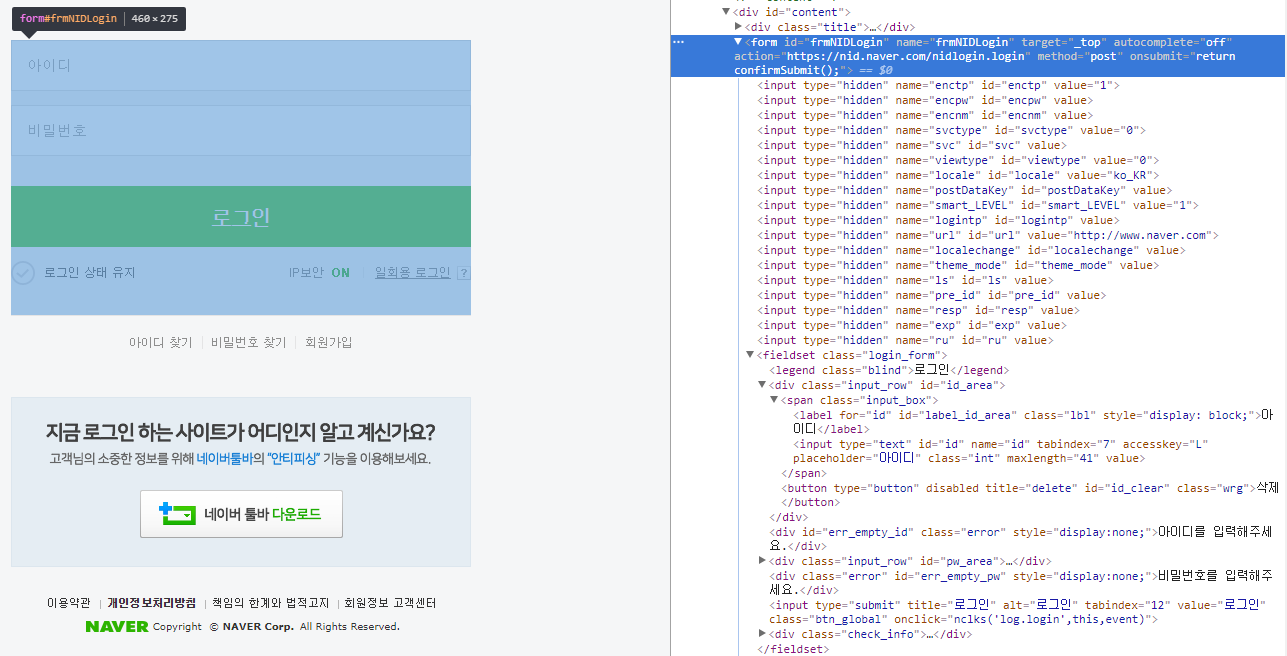
이제 스크립트를 통해 네이버에 자동으로 로그인하는 프로그램을 만들어보자.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
#---------------------------------------------------------------------------------------
# 브라우저 열기
driver = webdriver.Chrome('C:\\크롬\\드라이버를\\저장한\\절대경로')
driver.get("https://nid.naver.com/nidlogin.login")
#---------------------------------------------------------------------------------------
#---------------------------------------------------------------------------------------
# 로그인 하기
driver.find_element_by_name('id').send_keys('네이버 ID')
driver.find_element_by_name('pw').send_keys('네이버 PW')
# 로그인 버튼 클릭
driver.find_element_by_xpath('//*[@id="frmNIDLogin"]/fieldset/input').click()
#---------------------------------------------------------------------------------------
로그인하기의 선택자들은 BS4와 사용법이 비슷해서 이해가 쉽지만 마지막에 로그인 버튼 클릭하는 문법은 생소하다.
로그인 페이지 소스를 자세히보면 로그인 버튼에는 id나 name같은 선택자가 없다. 이런 경우에는 XPath(XML Path)를 사용한다. XPath는 XML 문서의 일부분을 탐색하고 선택하는데 사용하는 쿼리 언어다.
XPath문법은 크게 네가지 개념으로 이루어진다.
- 루트 노드 대 루트가 아닌 노드
- /div 는 오직 문서의 루트에 있는 div 노드만 선택한다.
- //div 는 문서의 어디에있든 모든 div노드를 선택한다. - 속성 선택
- //@href는 href 속성이 있는 모든 노드를 선택한다.
- //a[@href=’http:\/\/google.com’]는 구글을 가리키는 모든 링크를 선택한다. - 위치에따른 노드 선택
- (//a)[3]는 문서의 세 번째 링크를 선택한다.
- (//table)[last()]는 문서의 마지막 테이블을 선택한다.
- (//a)[position() < 3]는 문서의 처음 두 링크를 선택한다. - 아스테리스크(*)는 어떤 문자나 노드의 집합이든 선택한다.
- //table/tr/*은 모든 테이블에서 모든 자식 tr태그를 선택한다.
- //div[@*]는 속성이 하나라도 있는 모든 div태그를 선택한다.
물론 이것 말고도 고급기능이 많지만 이정도만 알아도 사용하는데 무리가 없다.
로그인 버튼의 태그 구조를 살펴보면
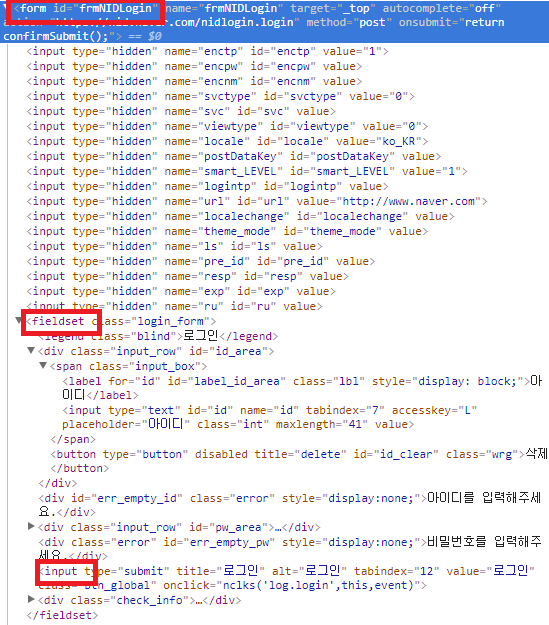
이렇게 생겼다.
이제 //*[@id="frmNIDLogin"]/fieldset/input이 코드가 조금은 이해가 가겠다.
위 코드를 실행하면 신기하게 크롬 브라우저 창이 뜬 뒤에 자동으로 로그인 폼이 입력되고 로그인 버튼도 눌러준다.
여기서는 로그인하는것만 다루었지만 이전 포스트에서 설명한 여러 예제들과 결합하면 멋진 웹 크롤러가 탄생할 것이다.
Congratulation
여러분은 이제 웹 페이지를 마음 껏 돌아다니며 원하는 데이터를 긁어올 수 있다!
나중에 중요하게 포스팅 하겠지만 스크립트를 절대로 아무 사이트나 돌아니면서 실행하면 안된다 절대로.
잘 보호된 일부 사이트는 폼을 너무 빨리 전송하거나 너무 빨리 행동한다면 막힐 수 있다. 일반적인 사용자보다 압도적으로 많은 정보를 가져가거나 요구해도 웹 마스터의 주의를 끌고 차단 당할 수 있다.
따라서 멀티스레드로 속도를 끌어올리는 것 보다는 time.sleep(3) 으로 몇 초 정도 간격을 두는게 좋다.
다른건 몰라도 이것만은 꼭 지키자. 서버 자원을 과도하게 사용하면 법적으로 불리해질 뿐만 아니라, 소규모 사이트같은 경우에는 서버가 다운되게 할 수도 있기때문이다.
웹 사이트를 다운시키는 것은 윤리적으로 모호한 상황이 아니다. 그건 완전히 잘못된 일이다. 주의하자.