Intro
이 포스트는 긁어온 데이터 저장하기 포스트에 의존합니다. 이전 포스트를 먼저 보시는걸 추천합니다.
우리는 지금까지 어느정도 정형화된 데이터 소스를 가지고 크롤링 실습을 해 보았다. 오류가있거나 정형화되지 않은 데이터는 아예 무시하고 크롤링하지 않았다. 하지만 이렇게 제한된 범위에서만 데이터를 수집하는걸로는 부족할 때가 있다.
잘못된 구두점, 일관성없는 대문자, 줄바꿈, 오타, 닫는 태그의 부재 등 지저분한 데이터는 웹 크롤링에서 큰 장애물이다. 이번 포스트에 도구와 테크닉 코드 작성 방법을 바꿔서 우리의 코드에서 문제가 발생하지 않도록하는 방법, 일단 DB에 들어온 데이터를 정리하는 방법을 알아보자.
코드로 정리하기
예외를 처리하는 코드도 중요하지만 예상 못 한 상황에 대응하는 방어적인 코드도 중요하다.
언어학에서 N-그램은 텍스트나 연설에서 연속으로 나타난 단어 n개를 말한다. 예를들어 I love Python이라는 문장에서 2-그램으로 나누면 [I], [love], [love], [python] 이렇게 나뉘게 된다. 보통 자연어를 분석할때 공통적으로 나타나는 n-그램으로 나누어 분석하는게 편리하다.
n-그램을 분석하는 방법은 다음포스트에서 알아보도록하고, 이번에는 정확한 형태를 갖춘 n-그램을 찾는 데 집중하자.
다음 코드는 파이썬 프로그래밍 언어에 관한 위키백과 항목에서 찾은 2-그램 목록을 반환한다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
def ngrams(input, n):
input = input.split(' ')
output = []
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return output
html = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(html, "html.parser")
content = bsObj.find("div",{"id":"mw-content-text"}).get_text()
ngrams = ngrams(content, 2)
print(ngrams)
print("2-grams count is : "+str(len(ngrams)))
ngrams 함수는 입력 문자열을 받고, 모든 단어가 공백으로 구분되었다고 가정하여 연속된 단어로 나눈 다음 n-그램 배열을 만들어 반환한다. 출력 결과는 다음과 같다.

제대로 된 2-그램 보다는 쓸모없는 것들이 잔뜩 들어있다. 마지막 단어를 제외하고 만나는 모든 단어에서 2-그램을 만들어 총 8782개의 2-그램이 만들어졌다.
정규표현식을 써서 \n같은 이스케이프 문자를 제거하고 유니코드 문자도 제거하면 어느정도 정리가 될 것 같다.
def ngrams(input, n):
#줄바꿈Xn = 공백
input = re.sub('\n+', " ", input)
#공백Xn = 공백
input = re.sub(' +', " ", input)
input = bytes(input, "UTF-8")
input = input.decode("ascii", "ignore")
print(input)
input = input.split(' ')
output = []
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return output
이 코드는 먼저 줄바꿈 문자를 모두 공백으로 바꾸고, 연속된 공백을 하나의 공백으로 합쳐서 모든 단어와 단어 사이에 공백이 하나만 있게 한다.
다음에는 컨텐츠 인코딩을 UTF-8으로 바꿔서 이스케이프 문자를 없앤다.
이 단계를 거치면 함수의 출력 결과가 크게 개선되지만, 여전히 몇가지 문제가 있다.
[‘Pythoneers.[43][44]’, ‘Syntax’], [‘7’, ‘/’], [’/’, ‘3’], [‘3’, ‘==’], [’==’, ‘2’]
이런 데이터를 처리하기 위해서는 몇가지 규칙이 더 필요하다
- i와 a를 제외한 단 한 글자로 된 ‘단어’는 모두 버려야한다
- 위키백과 인용 표시인 대괄호로 감싼 숫자도 버려야한다
- 구두점도 버린다
이 규칙까지 넣은 코드가 좀 길어졌으니 cleanInput함수로 분리했다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
def cleanInput(input):
input = re.sub('\n+', " ", input)
input = re.sub('\[[0-9]*\]', "", input)
input = re.sub(' +', " ", input)
input = bytes(input, "UTF-8")
input = input.decode("ascii", "ignore")
cleanInput = []
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'):
cleanInput.append(item)
return cleanInput
def ngrams(input, n):
input = cleanInput(input)
output = []
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return output
import string과 string.punctuation으로 파이썬이 구두점이라 생각하는 모든 글자의 리스트를 얻었다. 파이썬 터미널에서 string.punctuation의 결과를 확인할 수 있다.

컨텐츠의 모든 단어를 순회하는 루프 안에서 item.strip(string.punctuation)을 사용하면 단어 양 끝의 구두점을 모두 없앨 수 있다. 물론 하이픈이 들어간 단어는 바뀌지 않는다.
이제 훨씬 깔끔한 2-그램을 얻을 수 있다.
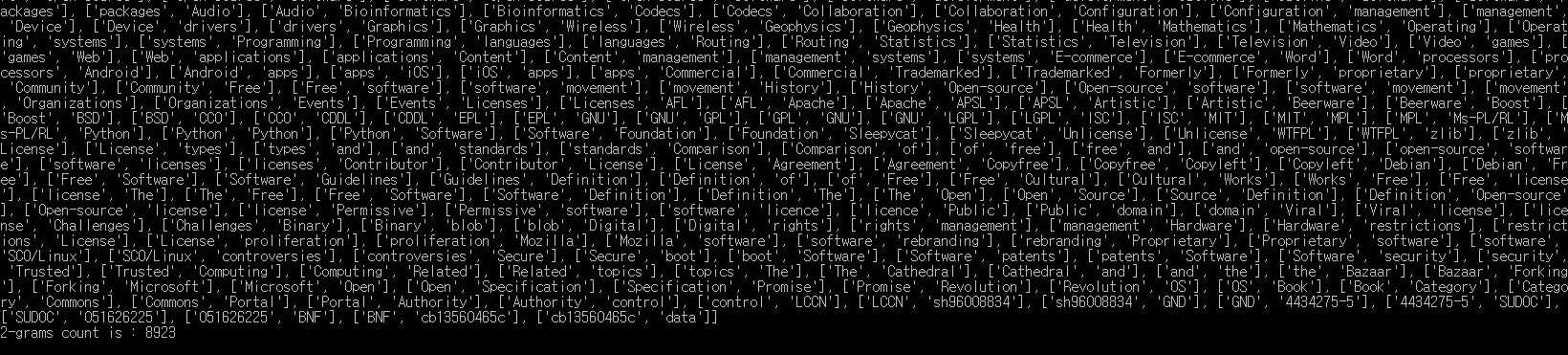
데이터 정규화
데이터 정규화란 언어학적으로 또는 논리적으로 동등한 문자열이 똑같이 표시되도록, 최소한 비교할 때 같은 것이라고 판단하게 하는 작업이다.
앞에서 본 n-그램 코드를 사용하면 데이터 정규화 기능을 사용할 수 있다.
물론 이 코드는 중복된 2-그램이 많다는 문제가 있다. 2-그램을 만나면 리스트에 추가할 뿐 빈도를 기록하지도 않는다. 빈도를 기록하고 중복을 없앤다면 데이터 정리 알고리즘이나 정규화 알고리즘을 바꿨을 때 어떤 효과가 있는지 알아보는 데 유용하다.
하지만 파이썬 딕셔너리는 정렬되지 않는다. 그렇기때문에 collections라이브러리에 들어 있는 OrderedDict를 사용하여 이 문제를 해결한다.
from collections import OrderedDict
...
ngrams = ngrams(content, 2)
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
print(ngrams)
여기서 파이썬의 sorted함수를 활용해 값을 기준으로 정렬해서 새 OrderedDict 객체에 넣었다.
사후 정리
코드에서 할 수 있는 일은 한계가있다. 내가 만들지 않았을 뿐더러 어떻게 처리할지 짐작도 안되는 데이터 셋을 다루게 될 수 도 있기때문이다.
이런 상황에서 많은 개발자들은 ‘스크립트를 만들자’라는 생각을 한다. 물론 뛰어난 해결책이 될 수도 있지만 우리는 다른 프로그램을 써보기로 하자.
오픈리파인
오픈리 파인은 메타웹 이라는 회사에서 2009년 시작한 오픈 소스 프로젝트이다. 현재는 구글이 인수하여 개발중이다.
오픈리파인의 인터페이스는 브라우저 안에서 동작하지만 데스크탑 애플리케이션 이므로 반드시 내려받아 설치해야 한다. 오픈리파인 웹사이트에서 리눅스와 윈도우, 맥 OS X용 애플리케이션을 내려받을 수 있다.
TIP.
맥 사용자인데 파일을 열때 문제가 있다면
‘시스템 환경설정 > 보안 및 개인정보 보호 > 일반’에서
‘다음에서 다운로드한 App허용’을 ‘모든 곳’으로 바꾸자.
오픈리파인을 사용하려면 데이터를 CSV 파일로 바꿔야한다.
오픈리파인 사용하기
일단 CSV파일을 만들자.
위키백과 텍스트에디터 비교 테이블을 긁어와 CSV파일로 저장하는 예제이다.
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://en.wikipedia.org/wiki/Comparison_of_text_editors")
bsObj = BeautifulSoup(html, "html.parser")
table = bsObj.findAll("table",{"class":"wikitable"})[0]
rows = table.findAll("tr")
csvFile = open("./editors.csv", 'wt', encoding='UTF-8')
writer = csv.writer(csvFile)
try:
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
finally:
csvFile.close()
이제 생성된 데이터를 오픈리파인에서 열어보자.

프로젝트를 새로 생성한 뒤의 화면이다. 각 열 레이블 다음에 있는 화살표는 필터링, 정렬, 변형, 데이터 제거가 가능한 도구 메뉴를 연다.
필터링
데이터 필터링에는 filter와 facet 두 가지 방법이 있다. filter는 정규 표현식을 써서 데이터를 거를 때 유용하다. 예를 들어 다음은 프로그래밍 언어 열에서 프로그래밍 언어 세 개 이상이 쉼표로 구분된 데이터만 보는 화면이다.
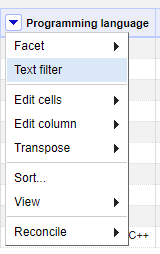 클릭! 하면
클릭! 하면
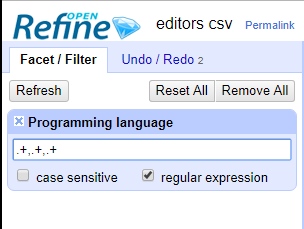 왼쪽에 이렇게 입력한다.
왼쪽에 이렇게 입력한다.
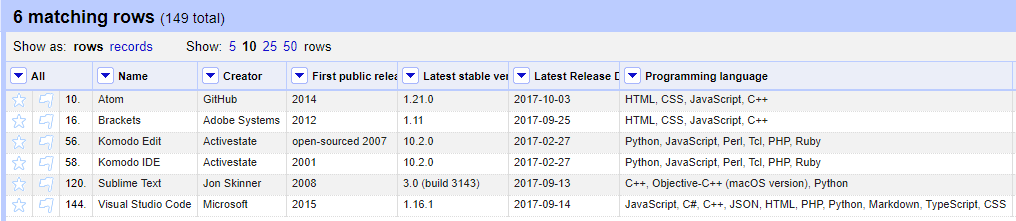 정규표현식 .+,.+,.+는 쉼표로 구분된 항목이 최소한 세 개 이상인 값만 선택한다.
정규표현식 .+,.+,.+는 쉼표로 구분된 항목이 최소한 세 개 이상인 값만 선택한다.
facet은 열의 콘텐츠 전체를 바탕으로 데이터를 제외하거나 포함하려 할 때 유용하다.
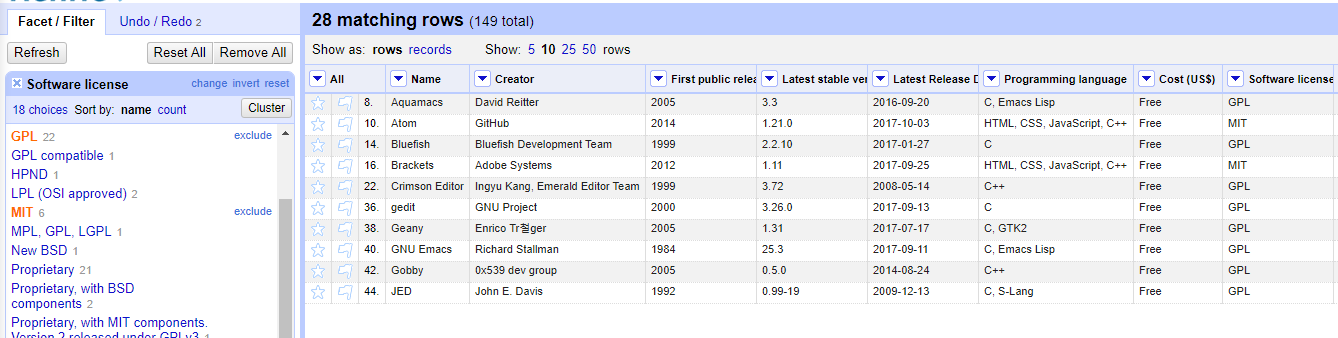 위 사진은 GPL이나 MIT 라이선스로 운영하는 에디터만 보는 화면이다.
위 사진은 GPL이나 MIT 라이선스로 운영하는 에디터만 보는 화면이다.
데이터를 어떤 식으로 필터링 했더라도 언제든지 오픈리파인이 지원하는 형식으로 내보낼 수 있다. 오픈리파인은 CSV, HTML, HTML 테이블, 엑셀 등 여러가지 다른 형식을 지원한다.